クリックで拡大表示
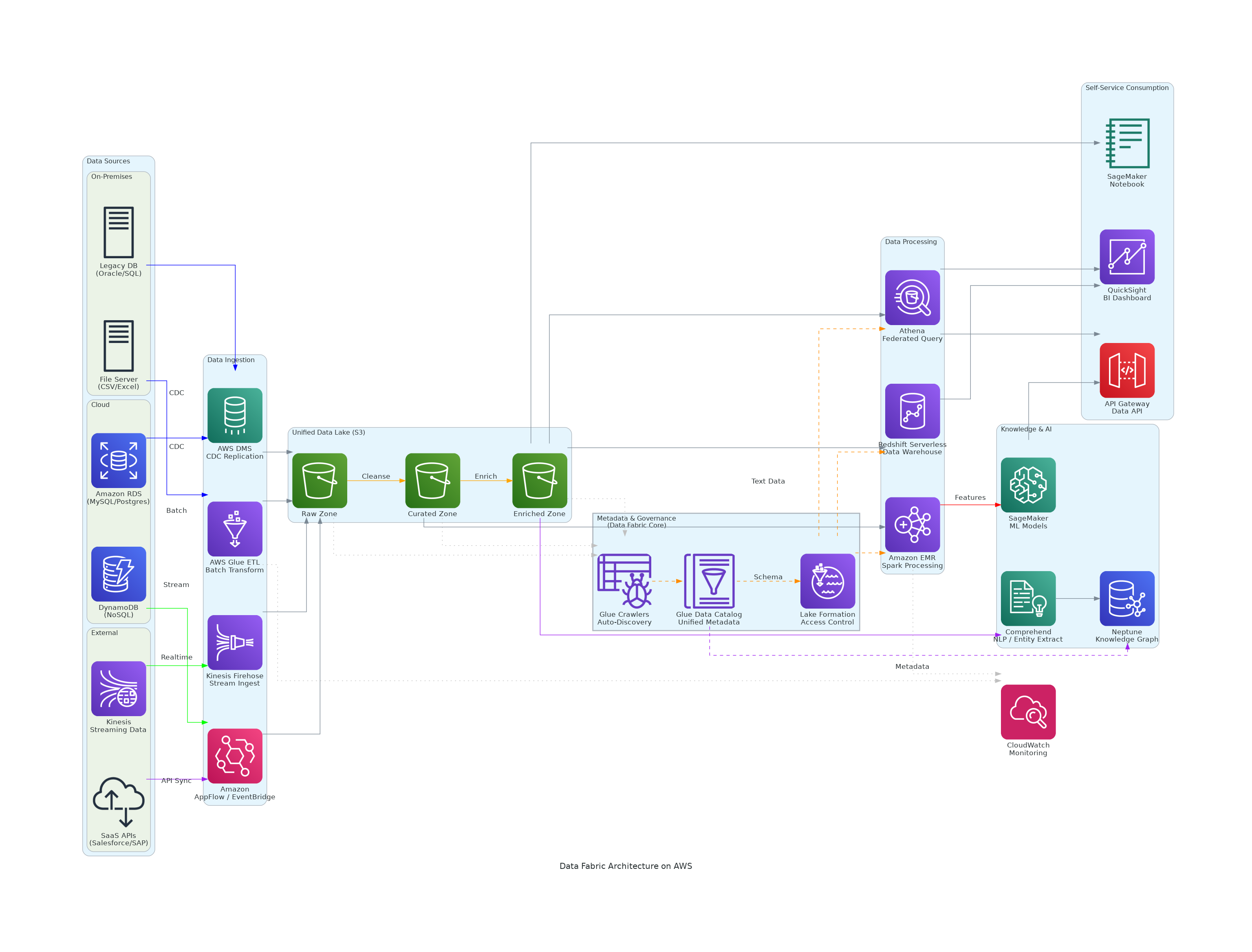
データファブリックは、組織内に分散する多様なデータソース(オンプレミスDB、クラウドDB、SaaS、ストリーミング)を統合的に管理し、セルフサービスでデータアクセスを提供するアーキテクチャパターンです。
従来のデータレイクハウス(Medallionアーキテクチャ)が「データの品質層を段階的に上げる」ことに焦点を置くのに対し、データファブリックは「分散データソースを横断的に発見・統合・ガバナンスする」ことに重点を置いています。AWS Glue Data Catalog + Lake Formation + Glue Crawlers がファブリックの核心層(Active Metadata Layer)を構成し、Neptune によるナレッジグラフがメタデータ間の関係性を可視化します。
| レイヤー | AWSサービス | 用途 |
|---|---|---|
| データソース | On-Prem DB, RDS, DynamoDB, SaaS APIs, Kinesis | バッチ・ストリーミング・API連携の3パターンで多様なソースに対応 |
| 取り込み Batch | AWS DMS, Glue ETL | CDC レプリケーション、バッチ変換・クレンジング |
| 取り込み Realtime | Kinesis Data Streams + Firehose | ストリーミングデータのリアルタイム取得と S3 配信 |
| 取り込み API | AppFlow / EventBridge | SaaS アプリケーションとのイベント連携 |
| 統合データレイク | Amazon S3 (Raw / Curated / Enriched) | 3ゾーン構成でデータ品質を段階管理 |
| メタデータ & ガバナンス (Data Fabric Core) | Glue Crawlers, Glue Data Catalog, Lake Formation | スキーマ自動検出、統合メタデータ管理、列/行レベルアクセス制御 |
| データ処理 | Athena (フェデレーテッドクエリ), Redshift Serverless, EMR | SQL分析、DWHクエリ、Spark分散処理 |
| ナレッジ & AI | Neptune, Comprehend, SageMaker | ナレッジグラフ、NLPエンティティ抽出、ML モデル |
| セルフサービス消費 | QuickSight, API Gateway, SageMaker Notebook | BIダッシュボード、データAPI、探索的分析 |
| 監視 | CloudWatch | ETLジョブ・処理エンジンのメトリクス・ログ |
ap-northeast-1 (東京) リージョン基準の月額概算。実際の費用は利用量により変動します。為替レート: $1 = 150円
| サービス | 構成 | Dev (月額) | Prod (月額) |
|---|---|---|---|
| AWS DMS | DB連携 | $20-40 (3,000-6,000円) | $40-80 (6,000-12,000円) |
| Kinesis Data Streams | ストリーミング (2-4 shard) | $30-60 (4,500-9,000円) | $60-150 (9,000-22,500円) |
| Kinesis Data Firehose | S3配信 | $5-15 (750-2,250円) | $15-60 (2,250-9,000円) |
| AppFlow | SaaS連携 | $1-5 (150-750円) | $5-20 (750-3,000円) |
| EventBridge | イベント統合 | $0-2 (0-300円) | $2-10 (300-1,500円) |
| S3 | データレイク (500GB-2TB) | $12-50 (1,800-7,500円) | $50-200 (7,500-30,000円) |
| Glue ETL + Crawlers | データ変換・カタログ化 | $15-60 (2,250-9,000円) | $60-300 (9,000-45,000円) |
| Lake Formation | ガバナンス | $0 (無料) | $0 (無料) |
| Athena | データ仮想化クエリ | $5-30 (750-4,500円) | $30-100 (4,500-15,000円) |
| Redshift Serverless | DWH | $50-150 (7,500-22,500円) | $200-600 (30,000-90,000円) |
| EMR | 大規模バッチ | $30-80 (4,500-12,000円) | $80-300 (12,000-45,000円) |
| Neptune | ナレッジグラフ | $50-100 (7,500-15,000円) | $100-300 (15,000-45,000円) |
| Comprehend | NLP処理 | $10-30 (1,500-4,500円) | $30-100 (4,500-15,000円) |
| SageMaker | ML推論 | $50-100 (7,500-15,000円) | $100-300 (15,000-45,000円) |
| API Gateway | データサービスAPI | $3-10 (450-1,500円) | $10-30 (1,500-4,500円) |
| CloudWatch | 監視 | $10-20 (1,500-3,000円) | $20-40 (3,000-6,000円) |
| 合計 | $291-752 (約43,650-112,800円) | $802-2,590 (約120,300-388,500円) | |
前提条件: Dev=500GBテストデータ、Prod=2TB。複数データソース(RDB/NoSQL/SaaS/ストリーム)の統合。Neptuneはdb.r5.large想定。
コスト最適化: EMR SpotインスタンスでETLバッチコスト90%削減。S3 Lifecycle PolicyでCold→Glacier移行。Athena Federated Queryで不要なデータコピーを削減。Neptune最小インスタンスで開始し需要に応じてスケール。
1. Active Metadata Layer がファブリックの核心
Glue Crawlers が S3 全ゾーンを自動スキャンしてスキーマを検出、Glue Data Catalog に統合メタデータとして登録。Lake Formation がカタログ全体のアクセス制御を一元管理する。この3層がデータファブリックの「織物(fabric)」の役割を果たし、分散データを論理的に統合する。
2. フェデレーテッドクエリによるデータ仮想化
Athena のフェデレーテッドクエリにより、S3・Redshift・外部DBを物理的に移動せず横断的にSQLクエリが可能。データの実体はソースに残したまま、仮想的に統合アクセスを実現する。
3. Neptune ナレッジグラフによるメタデータの関係性可視化
Glue Data Catalog のメタデータと Comprehend の NLP エンティティ抽出結果を Neptune に投入し、テーブル間・エンティティ間の関係性をグラフで管理する。データリネージの追跡やインパクト分析が可能になる。
4. 3取り込みパターンによるソース多様性対応
バッチ(DMS/Glue ETL)、ストリーミング(Kinesis)、API連携(AppFlow/EventBridge)の3経路を設計。オンプレミスDB・クラウドDB・SaaS・IoTデバイスなど、あらゆるデータソースに対応。新規ソース追加時も取り込み層の拡張のみで対応可能。
5. セルフサービスによるデータ民主化
QuickSight(BI)、API Gateway(プログラマティックアクセス)、SageMaker Notebook(データサイエンティスト向け)の3消費チャネルを用意。Lake Formation のポリシーが全チャネルに適用されるため、セルフサービスでありながらガバナンスを維持。
| 観点 | Data Lakehouse(Medallion) | Data Fabric(本構成) |
|---|---|---|
| 主眼 | データ品質の段階的向上 | 分散データの統合管理・発見・ガバナンス |
| メタデータ | ETL処理のカタログ管理 | Active Metadata(自動検出・関係性グラフ) |
| データ移動 | 必ず S3 に集約 | フェデレーテッドクエリで移動不要も可 |
| AI活用 | 分析結果の可視化 | メタデータ自体の AI 分析・推薦 |
| 適合ケース | 単一データソースの品質管理 | 複数組織・複数ソースの横断統合 |
Powered by AWS Diagram MCP Server | Reviewed by AWS Knowledge MCP Server