クリックで拡大表示
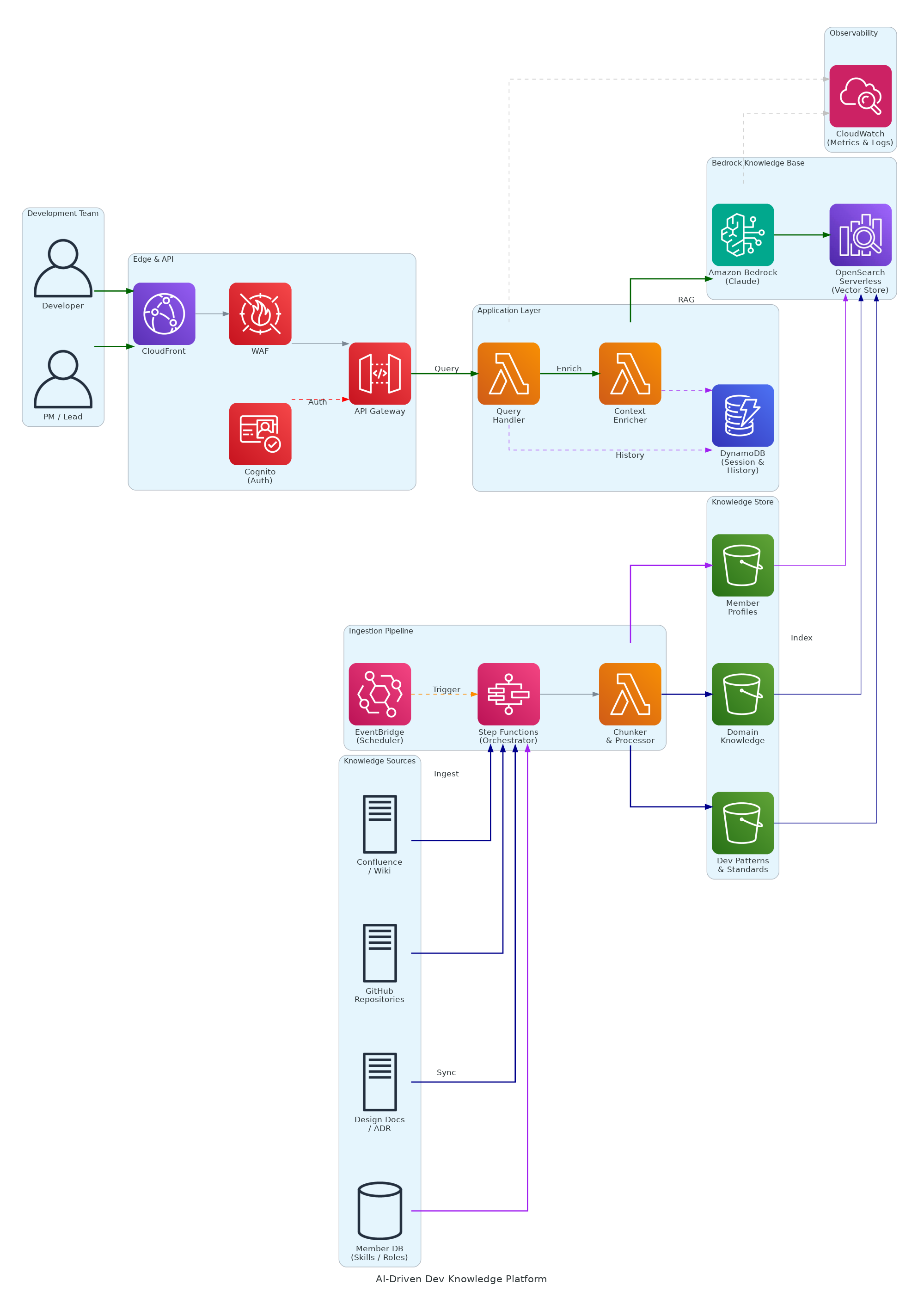
Amazon Bedrockのナレッジベース機能(RAG)を活用し、組織内に分散するドメイン知識・開発ナレッジ・メンバースキル情報を統合的に蓄積・検索できるプラットフォームです。
開発者やPMが自然言語で質問するだけで、社内の設計書・ADR・開発パターン・メンバーのスキル情報を横断的に検索し、AI が文脈を理解した上で回答を生成します。AI駆動開発における「誰に聞けばいいか」「過去に同じ課題をどう解決したか」「このドメインの制約は何か」といった問いに即座に答え、開発の精度と効率を底上げします。
| レイヤー | AWSサービス | 用途 |
|---|---|---|
| データソース | Confluence, GitHub, 設計書, メンバーDB | ドメイン知識・開発パターン・ADR・スキル情報の4種類のナレッジソース |
| 取り込み Ingest | Step Functions + Lambda | ドキュメントの取得・チャンク分割・前処理・Embedding生成のオーケストレーション |
| ナレッジストア | Amazon S3(3バケット) | ドメイン知識・開発パターン&標準・メンバープロフィールを分離管理 |
| ベクトルDB | OpenSearch Serverless | Embedding のインデックスと類似度検索。Bedrock Knowledge Base のバックエンド |
| AI Core | Amazon Bedrock (Claude) | RAG による回答生成。ナレッジベースから関連文脈を取得し、自然言語で回答 |
| エッジ / API | CloudFront, WAF, API Gateway | CDN配信・L7攻撃防御・REST APIエンドポイント |
| 認証 Auth | Cognito | 開発チームメンバーの認証・JWT発行 |
| アプリケーション | Lambda (Query Handler + Context Enricher) | クエリ受付、会話履歴からの文脈補強、Bedrock呼び出し |
| セッション Session | DynamoDB | 会話履歴・セッション管理。文脈を維持した連続的な対話を実現 |
| 自動化 Schedule | EventBridge | 定期的なナレッジ再同期(日次/週次)をスケジュール実行 |
| 監視 Observe | CloudWatch | Lambda実行・Bedrock呼び出し・APIレイテンシの監視・アラート |
| ナレッジ種別 | データソース | AI駆動開発での活用シーン |
|---|---|---|
| ドメイン知識 | Confluence, 要件定義書, 業務フロー | 「この業界の規制要件は?」「A社の業務フローの制約は?」→ 設計判断の精度向上 |
| 開発ナレッジ | GitHub, ADR, 設計書, コーディング規約 | 「過去に同じ課題をどう解決した?」「このパターンの推奨実装は?」→ 実装効率の向上 |
| メンバー情報 | スキルDB, プロジェクト履歴, 担当領域 | 「Kubernetes に詳しいメンバーは?」「このドメインの経験者は?」→ 最適なアサイン・相談先 |
ap-northeast-1 (東京) リージョン基準の月額概算。実際の費用は利用量により変動します。為替レート: $1 = 150円
| サービス | 構成 | Dev (月額) | Prod (月額) |
|---|---|---|---|
| Step Functions | RAGパイプライン | $1-5 (150-750円) | $5-20 (750-3,000円) |
| Lambda | 文書処理・検索関数 | $0-5 (0-750円) | $5-30 (750-4,500円) |
| S3 | ドキュメントストレージ | $2-5 (300-750円) | $5-20 (750-3,000円) |
| OpenSearch Serverless | ベクトル検索 | $50-100 (7,500-15,000円) | $100-300 (15,000-45,000円) |
| Bedrock | Embedding + 生成AI | $20-80 (3,000-12,000円) | $80-400 (12,000-60,000円) |
| CloudFront + WAF | フロントエンド配信 + セキュリティ | $11-20 (1,650-3,000円) | $25-65 (3,750-9,750円) |
| API Gateway | バックエンドAPI | $3-10 (450-1,500円) | $10-30 (1,500-4,500円) |
| Cognito | ユーザー認証 | $0 (無料枠内) | $0-25 (0-3,750円) |
| DynamoDB | メタデータ・セッション | $5-10 (750-1,500円) | $10-50 (1,500-7,500円) |
| EventBridge | ドキュメント更新イベント | $0-2 (0-300円) | $2-5 (300-750円) |
| CloudWatch | ログ + メトリクス | $5-10 (750-1,500円) | $10-20 (1,500-3,000円) |
| 合計 | $97-247 (約14,550-37,050円) | $252-965 (約37,800-144,750円) | |
前提条件: Dev=ドキュメント1,000件・月間クエリ1万件、Prod=10,000件・月間10万件。Bedrock Claude Haiku + Titan Embedding。OpenSearch Serverless最小2 OCU。
コスト最適化: OpenSearch Serverlessの最小OCU数に注意(Dev環境でも$50/月〜)。Bedrockはバッチ推論でコスト50%削減可。ドキュメントの差分Embeddingで再計算を最小化。
1. Bedrock Knowledge Base によるマネージドRAG
Bedrock の Knowledge Base 機能を使うことで、Embedding生成・ベクトルインデキシング・類似検索・回答生成のRAGパイプラインをフルマネージドで実現。自前でRAGインフラを構築・運用する必要がなく、ナレッジの追加は S3 にドキュメントを配置するだけ。
2. 3種のナレッジを分離管理
ドメイン知識・開発ナレッジ・メンバー情報を個別の S3 バケットで管理。ナレッジ種別ごとに更新頻度やアクセス制御が異なるため、分離することで運用の柔軟性を確保。クエリ時には OpenSearch のフィルタリングで特定種別に絞った検索も可能。
3. Context Enricher による文脈補強
Query Handler と Bedrock の間に Context Enricher Lambda を配置し、DynamoDB の会話履歴から直近の文脈を付加。「さっき聞いた設計書の件だけど」のような連続的な対話を実現し、AI駆動開発での自然な対話体験を提供。
4. EventBridge による定期的なナレッジ同期
Confluence・GitHub・メンバーDBは常に更新されるため、EventBridge で日次/週次の定期同期をスケジュール。Step Functions がパイプライン全体をオーケストレーションし、差分のみを効率的に再インデキシング。
5. 全サーバーレスによるゼロ運用負荷
Lambda・S3・OpenSearch Serverless・DynamoDB・Step Functions・EventBridge はすべてサーバーレス。インフラ管理が不要で、AI駆動開発チームは「ナレッジを溜めて使う」という本質的な活動に集中できる。
Powered by AWS Diagram MCP Server | Reviewed by AWS Knowledge MCP Server